AMD Ryzen 7 1800X, 1700X and 1700 Processor Review
Memory Subsystem Performance
So, Ryzen has solid memory bandwidth, but the latency scores made us want to look closer at how Ryzen’s integrated memory controller and the new cache hierarchy works. Ryzen 7 processors have a really interesting design as the 16MB L3 cache is sliced up two 8MB halves, due to the way the two CCX’es are connected to the L3 cache. So, while AMD advertises that Ryzen 7 CPUs have 16MB L3 cache it isn’t all in one location. So, you have 8MB per pair of CCX (L3) plus 1MB per CCX (L2) and that adds up to 20MB of cache on the Ryzen 7 processor. 8+8=16, plus 4×1 per CCX = 20MB total.
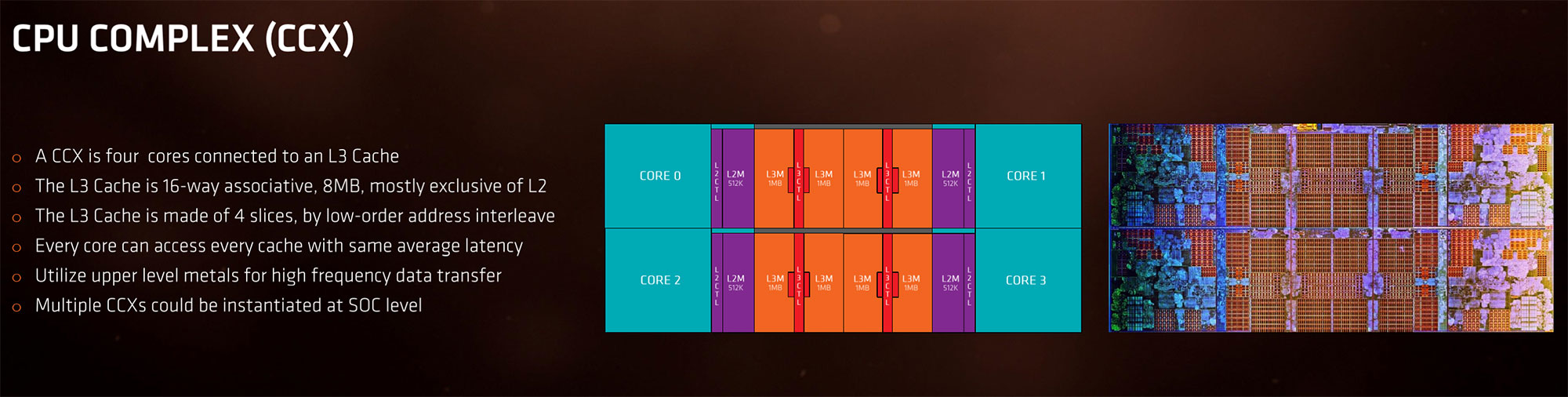
We also learned the L2 caches are not shared by all CUs in the CCX. Each CU in the CCX has 512KB available to it, for a total of 2MB of L2 per CCX. The L3 is shared by all CUs in the CCX, so a single CU can allocate to the entire 8MB L3. That means a single CU can access up to 512KB of L2 and 8MB of L3, even though the die will have 4MB of L2 and 16MB of L3.


Complicated, but a neat design if it works well. Let’s take a look at some Memory & Cache Latency testing using Linear Forward and Full Random workloads.
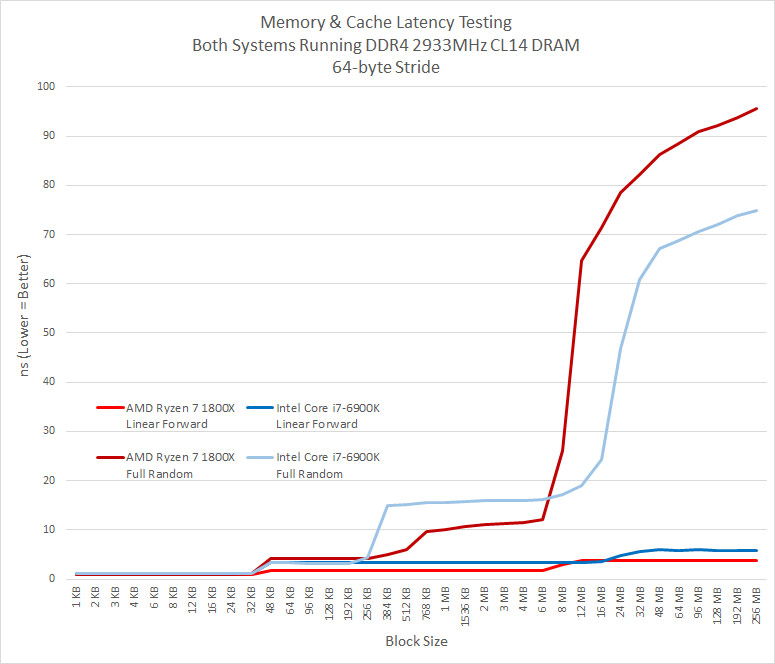
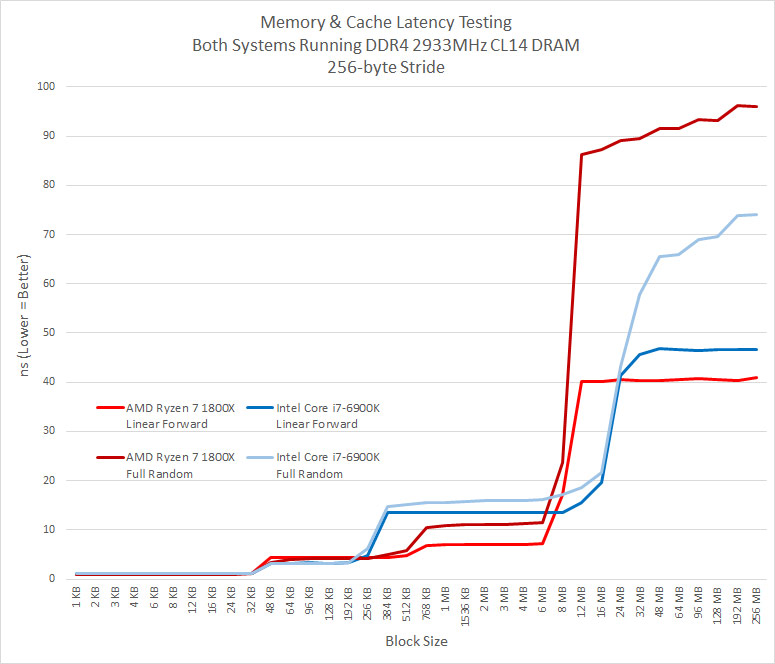
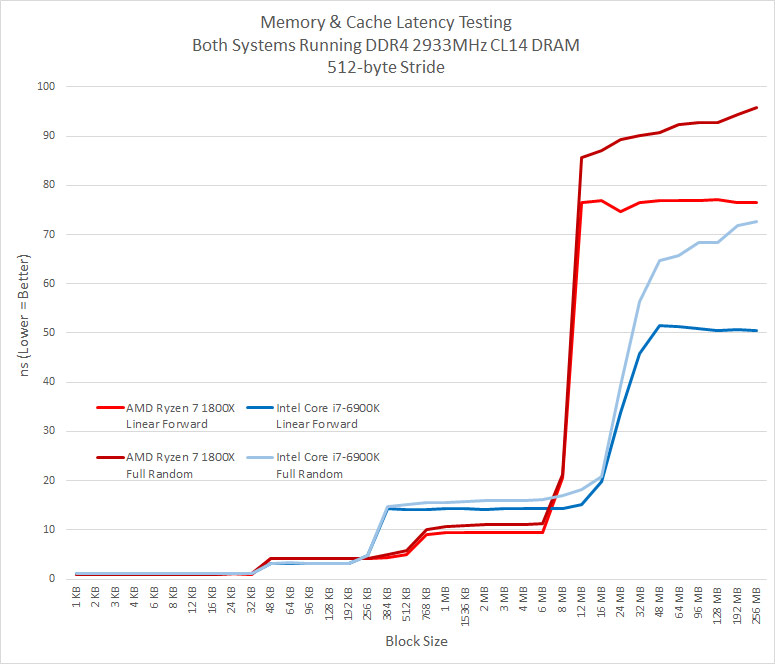
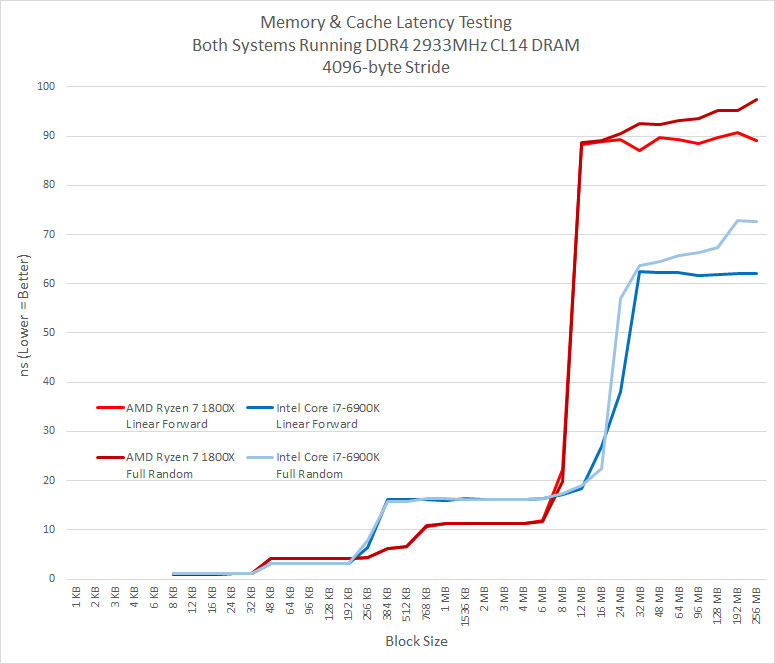
Cache Latency Results Summary: These results are totally unexpected as it looks like the 16MB of L3 cache on the Ryzen 7 1800X processor was just 8MB sized and that 8MB belonging to the other CCX wasn’t even there. It doesn’t even act like if it was a “L4” cache Very weird. Applications like Blender, Lightroom, and video transcoding doesn’t use any no or very little CCX communication. 7-Zip (real world compression of mixed data) and games do, so this might be a weak point for Ryzen. When we showed AMD these results they pointed outu that when youre not hitting in the L3 cache, their prefetchers (linear forward) look like theyre beating Intels (linear forward) for predictable access patterns, hiding a lot of memory latency.
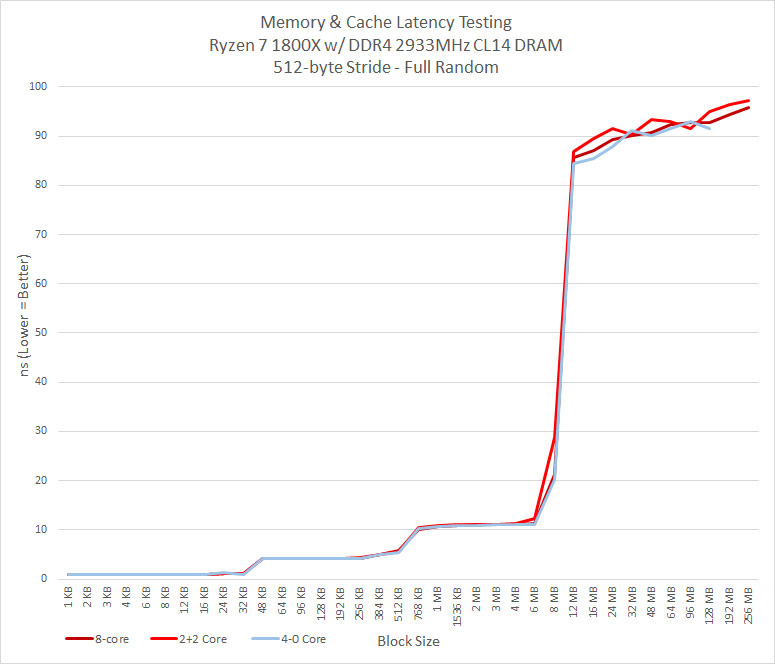
One of the neat things about a Ryzen platform is that you can disable cores and if you wanted to run just four cores you can select a 4-0 or 2-2 core setup on your CPU with a Ryzen 7 series processor. We thought some cache was attached per core, so disabling cores should change our benchmark results. Running all four cores on one half of the die (4-0) might have disabled the cache on one of the CCX’s and we proved that to be the case here as there were no results in the 192 MB and 256 MB block sizes. the maximum block size is LLC * 16. So when you have a 8MB L3 cache (or 8MB per CCX), the maximum block size is 128MB that they test will run to. Since we were getting results up to 256MB on the tests it looks like both blocks of 8MB cache per CCX was being accessed. This is a good sign, but there is a significant performance hit after 8MB for some reason. It would be nice to benchmark the speed between the two CCX’s as they are independent and connected with each other only through the SDF (Scalable Data Fabric). Could the interconnect between the two CCX’s be bottlenecking performance? We aren’t sure of a way to test that, but it sure looks like it.