NVIDIA Turing Architecture Overview – The Heart of GeForce RTX
Last month, NVIDIA CEO Jensen Huang unveiled the GeForce RTX 2000 series graphics cards ahead of Gamescom in Cologne, Germany. The RTX 2000 series is exciting not only because it is the first new GPU series from NVIDIA in over two years, but also because it is using the new Turing GPU. The NVIDIA Turing GPU has been redesigned from the ground up with new features and capabilities that will taking gaming to the next level. Some of the new RTX technologies announced by Jensen on the RTX 2070/2080/2080 TI cards was real-time hardware accelerated ray tracing and Deep Learning Super Sampling (DLSS) that uses the power of deep learning and AI to train the GPU to render crisp images. After the big unveiling of the GeForce RTX Series the media that was on-hand at the event were invited for a deep dive on the Turing GPU architecture.
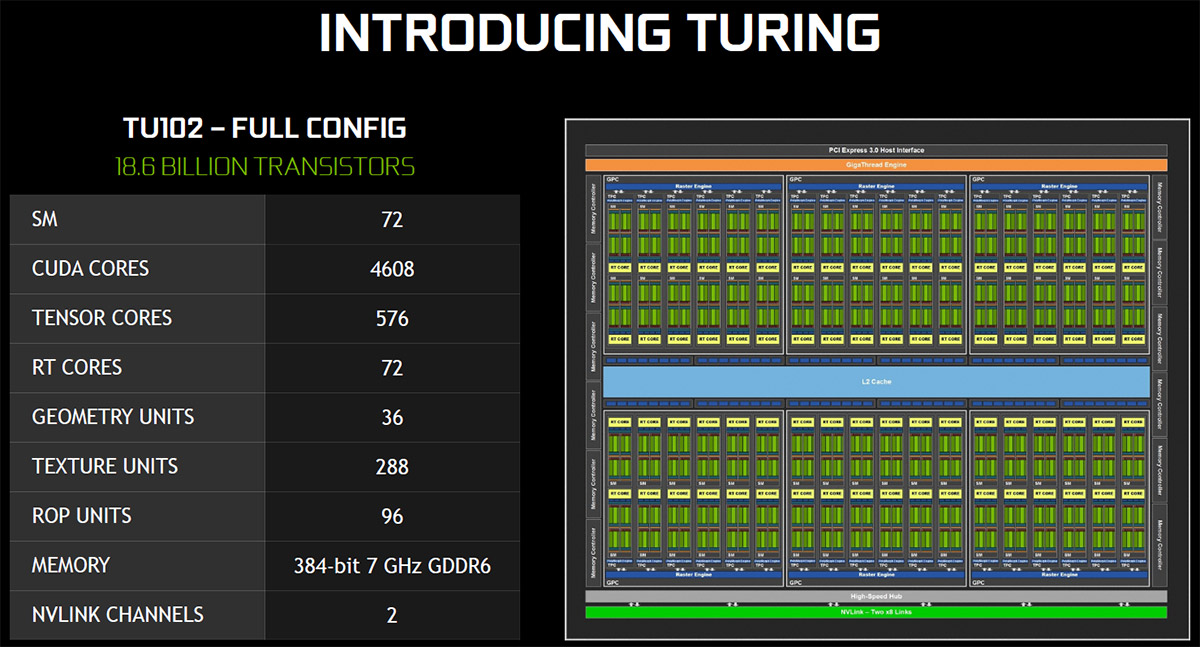
All three of the new high-end GeForce RTX series cards use the Turing GPU architecture, but each uses a different variant of the GPU. The GeForce RTX 2080 Ti is built using the TU102 GPU, the RTX 2080 is built on the TU104, and the RTX 2070 the TU106. There are 18.6B transistors on the Turing TU102 GPU and when fully featured it consists of six Graphics Processing Clusters (GPCs), 36 Texture Processing Clusters (TPCs) 72 Streaming Multiprocessors (SMs), 4,608 CUDA cores, 576 Tensor cores, 72 RT (Ray Tracing) cores, 288 texture units, 96 ROPs, a 384-bit memory interface, and dual NVLink channels. Sadly, only the NVIDIA Quadro RTX 6000 graphics card have this fully featured TU102 GPU.
The flagship NVIDIA GeForce RTX 2080 Ti cards use a slightly cut down version that has just 34 TPCs, 68 SMs, 4,352 CUDA cores and 68 RT cores, 272 texture units, 88 ROPS and a 352-bit memory interface. The table below will help show the differences between the flagship Pascal and Turing offerings for gamers and professional users. The GeForce RTX 2080 and RTX 2070 have the same feature-set, but their core counts and memory configurations have been further reduced.
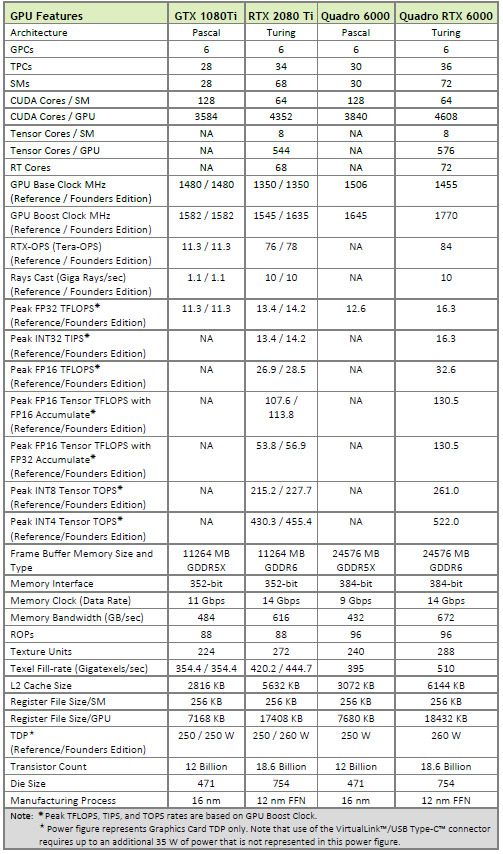
NVIDIA has an 8,000+ word in-depth blog post up that goes over the Turing Architecture and they have also released a white paper on the NVIDIA Turing GPU Architecture that is 87 pages in length. The level of detail about the Turing architecture in those two resources is amazing, so we’ll just be just highlighting a handful of things and get back to benchmarking the RTX 20 series cards.

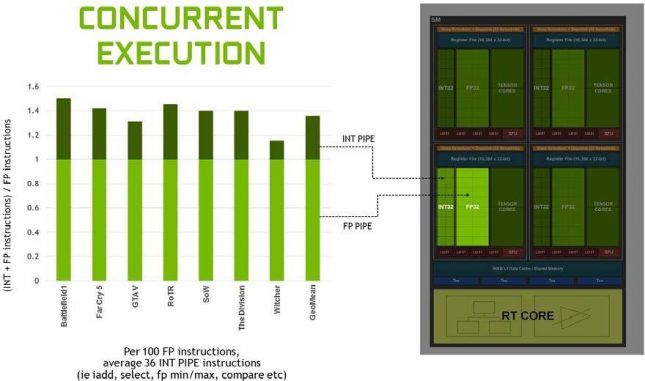
The Turing architecture features a new SM design that was derived from the Volta GV100 SM architecture. Two SMs are included per TPC, and each SM has a total of 64 FP32 Cores and 64 INT32 Cores. In comparison, the Pascal GPUs have one SM per TPC and 128 FP32 Cores per SM. Each Turing SM also includes eight mixed-precision Turing Tensor Cores and one RT Core. The Turing SM is partitioned into four processing blocks, each with 16 FP32 Cores, 16 INT32 Cores, two Tensor Cores, one warp scheduler, and one dispatch unit. The inclusion of INT32 cores allows the GPU execute INT32 and FP32 instructions simultaneously. This concurrent execution of different workloads allows for more efficiency as more work is being processed in a fewer number of clock cycles.
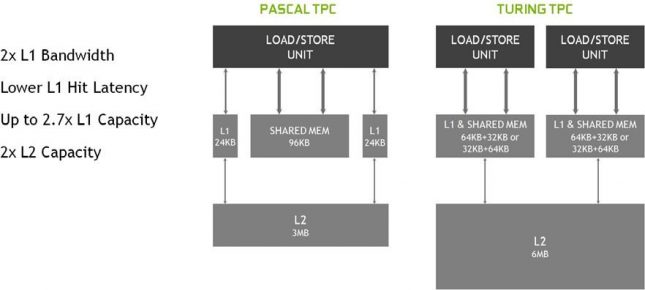
Turings SM also introduces a new unified architecture for shared memory, L1, and texture caching. Pascal GPUs had split L1 cache access on the memory subsystem, so NVIDIA has moved to a larger unified solution on Turing that is configurable on the fly. NVIDIA also doubled the size of the L2 cache from 3MB up to 6MB.
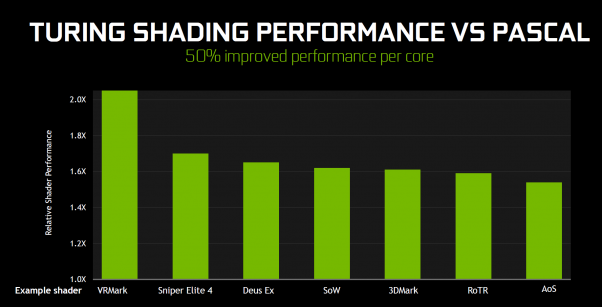
So, NVIDIA is seeing a 50% shading performance improvement per SM over Pascal thanks to Turing being able to handle simultaneous execution of both INT32 and FP32 instructions, as well as the changes to the memory architecture.
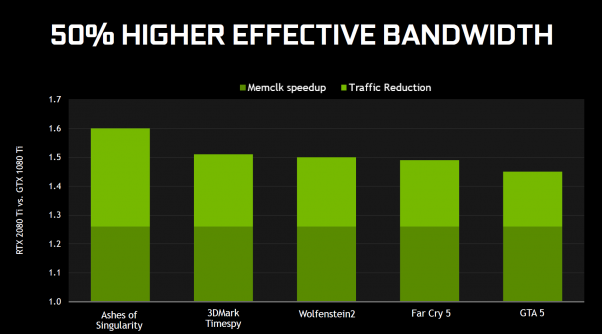
While we are talking about the memory subsystem, we should also note that Turing memory interface is using GDDR6 and that is an industry first. emory subsystem, Turing also sees a different memory interface, in GDDR6. NVIDIA is running the GDDR6 memory at 14Gbps, which is almost 30% faster than the GDDR5X 11 Gbps memory used on the GeForce GTX 1080 Ti. GDDR6 memory is also 20% more power efficient to boot and has 40% less signal crosstalk than GDDR5X.
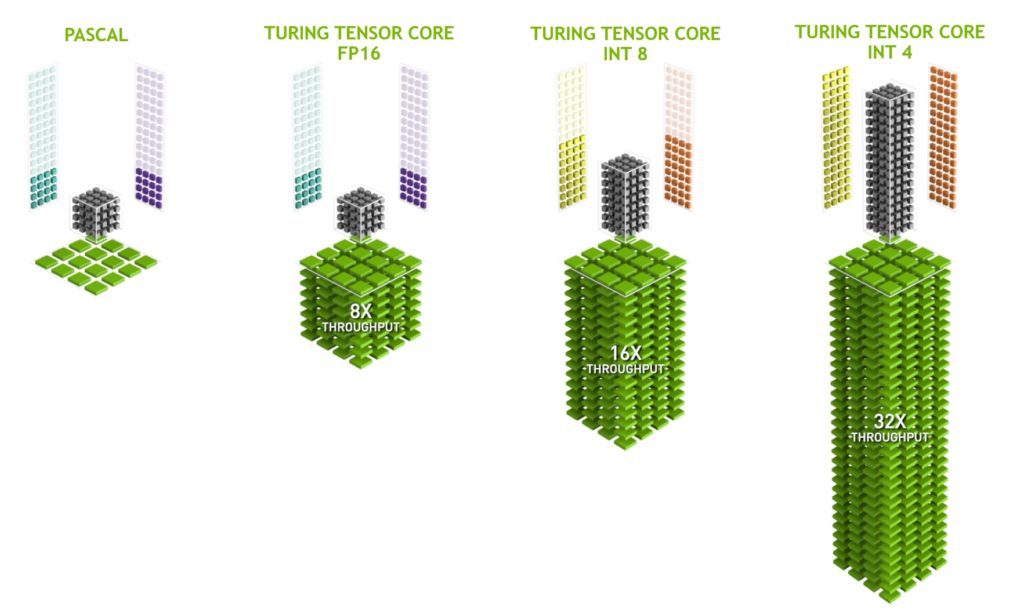
Turing GPUs also bring Tensor Cores gamers for the very first time. The introduction of Tensor Cores into Turing-based GeForce RTX graphics cards makes it possible to bring real-time deep learning to gaming applications like Deep Learning Super Sampling (DLSS) for the first time. The Turing Tensor Core design adds INT8 and INT4 precision modes for inferencing workloads that can tolerate quantization. FP16 is also fully supported for workloads that require higher precision. Turing with 4K DLSS offers twice the Performance of Pascal with 4K TAA. This is because TAA renders at the final target resolution and then combines frames, subtracting detail. DLSS allows faster rendering at a lower input resolution, and then infers a result that at target resolution is similar quality to the TAA result, but with half the shading work.
Right now there are 25 game titles that will be supporting DLSS shortly:
- Darksiders III from Gunfire Games / THQ Nordic
- Deliver Us The Moon: Fortuna from KeokeN Interactive
- Fear The Wolves from Vostok Games / Focus Home Interactive
- Hellblade: Senua’s Sacrifice from Ninja Theory
- KINETIK from Hero Machine Studios
- Outpost Zero from Symmetric Games / tinyBuild Games
- Overkill’s The Walking Dead from Overkill Software / Starbreeze Studios
- SCUM from Gamepires / Devolver Digital
- Stormdivers from Housemarque
- Ark: Survival Evolved from Studio Wildcard
- Atomic Heart from Mundfish
- Dauntless from Phoenix Labs
- Final Fantasy XV: Windows Edition from Square Enix
- Fractured Lands from Unbroken Studios
- Hitman 2 from IO Interactive / Warner Bros.
- Islands of Nyne from Define Human Studios
- Justice from NetEase
- JX3 from Kingsoft
- Mechwarrior 5: Mercenaries from Piranha Games
- PlayerUnknowns Battlegrounds from PUBG Corp.
- Remnant: From The Ashes from Arc Games
- Serious Sam 4: Planet Badass from Croteam / Devolver Digital
- Shadow of the Tomb Raider from Square Enix / Eidos-Montral / Crystal Dynamics / Nixxes
- The Forge Arena from Freezing Raccoon Studios
- We Happy Few from Compulsion Games / Gearbox
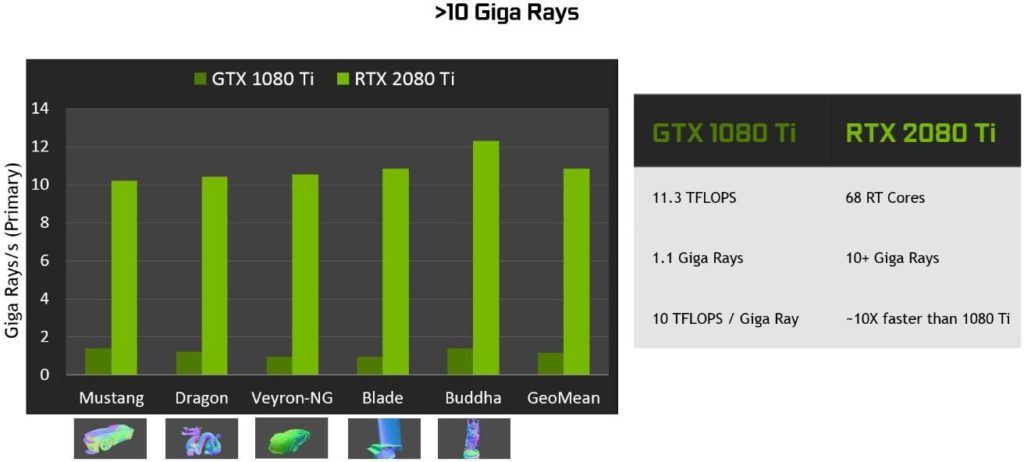
There are also RT Cores in Turing TU102, TU104, and TU106 GPUs and when used with NVIDIA RTX software technology we get real-time ray tracing on GPU. RT Cores accelerate Bounding Volume Hierarchy (BVH) traversal and ray/triangle intersection testing (ray casting) functions. RT Cores perform visibility testing on behalf of threads running in the SM.
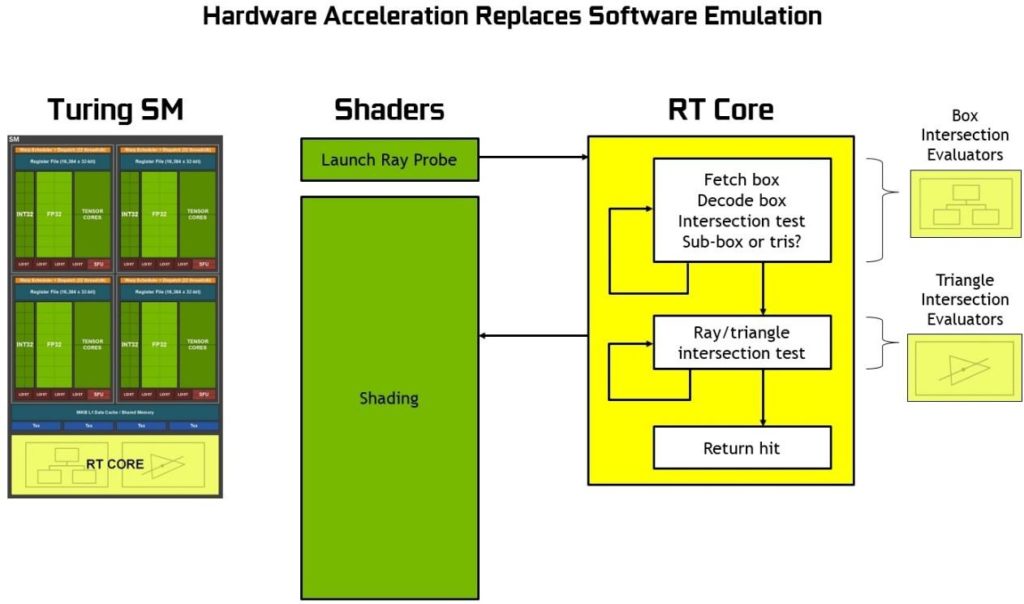
Pascal is spending approximately 1.1 Giga Rays/Sec, or 10 TFLOPS / Giga Ray to do ray tracing in software, whereas Turing can do 10+ Giga Rays/Sec using RT Cores, and run ray tracing 10 times faster.
You can see the Battlefield V Real-Time ray tracing demo on the GeForce RTX 2080 Ti below.
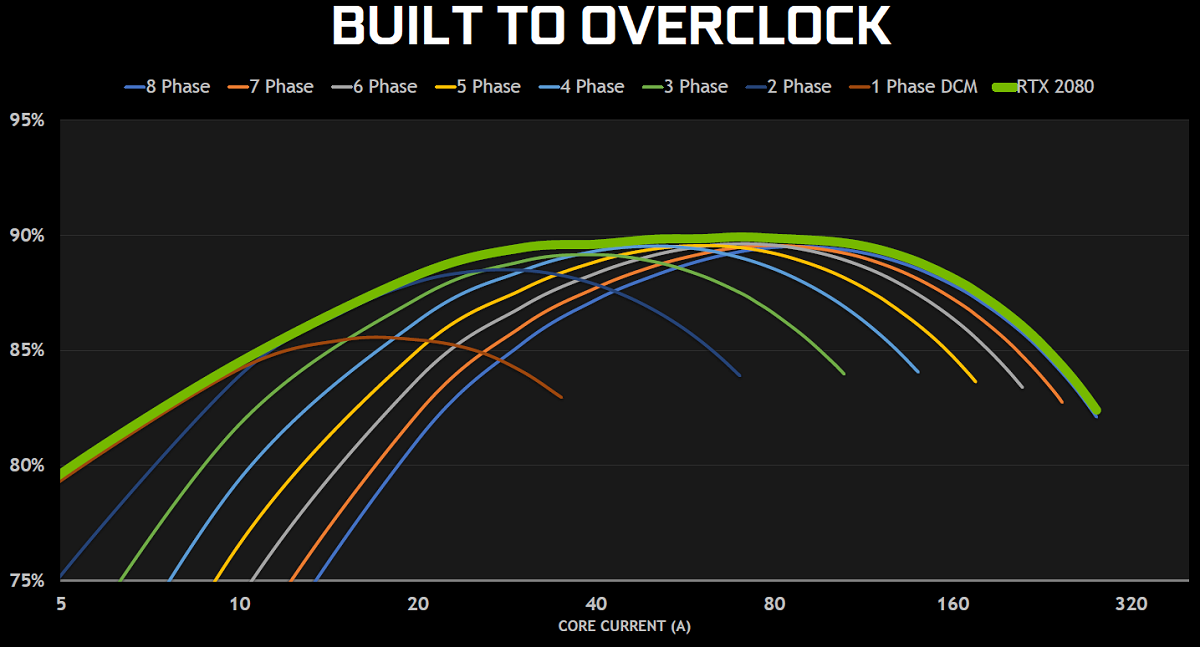
The NVIDIA GeForce RTX Turing cards are also built to overclock and feature automated overclocking with NVIDIA Scanner. NVIDIA Scanner will implemented into programs like EVGA Precision X1 and MSI Afterburner, sp automated overclocking of RTX-based graphics cards will be normal. NVIDIA also built their Founders Edition models to overclock with cleaner power delivery and more power headroom than ever before.
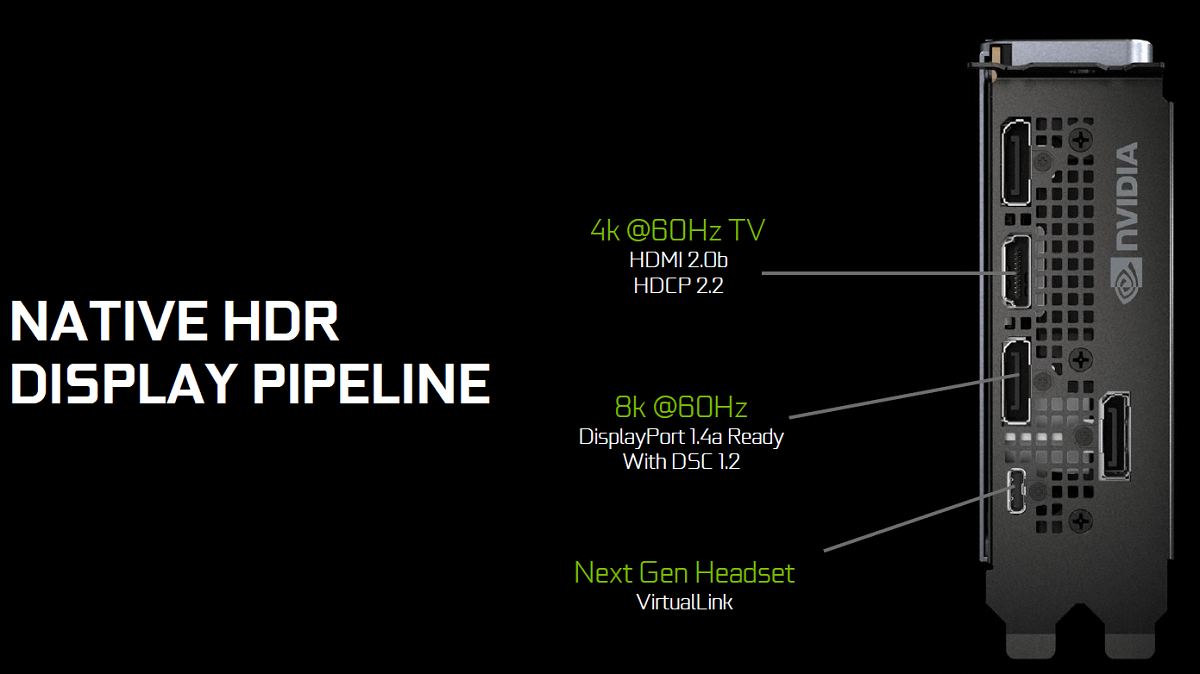
Turing GPUs include hardware support for USB Type-C and VirtualLink. (In preparation for the emerging VirtualLink standard) Many next-generation VR headsets are planning on using a single USB-C connector and can pull up to 35 Watts of power through this port. NVIDIA does not include this power draw in the TDP rating of their cards. So, the RTX 2080 TI Founders Edition card has a 260W TDP and you could pull 35 Watts on top of that when using VirtualLink.
It should be noted that Turing TU102 and TU104 GPUs incorporate NVIDIAs NVLink high-speed interconnect (100GB/sec of bidirectional bandwidth) to provide multi-GPU support for two Turing GPUs. This means that the RTX 2080 Ti and RTX 2080 can be paired NVLINKs increased bandwidth and dedicated inter-GPU channel enables data the ability to be split across the frame buffer of both GPUs, offering up to 22 GB of shared frame buffer memory (two 11 GB GeForce RTX 2080 Ti GPUs). Don’t call this SLI as NVLink has hardware based changes
The NVIDIA GeForce RTX NVLink Bridge runs $79.99 and is available in 3-slot and 4-slot sizes. Others companies will be making NVLink bridges and we expect to see some of those being announced on September 20th when the cards are available to ship.

The NVIDIA GeForce RTX Turing GPU architecture is impressive from the sounds of it and has a number of new features and capabilities over the Pascal GPU architecture. We currently have GeForce GTX cards in-house for testing and will be bringing you our benchmark results next week, so stay tuned! We are grinding away testing a whole bunch cards on over a dozen different game titles and applications and can’t wait to share the results with the community ahead of the cards retail availability on September 20th.
