ATI X1000 Series Video Card Roundup
Under The Hood

The new X1000 series is based completely on 128-bit Floating Point precision. There is no fallback to 64-bit (FP16) precision in the pipeline. The X1000 series will operate at FP32 at all times. Even if a partial precision hint is included in the code, the cards will simply ignore it and continue to run at FP32. There is no FP16 or lower precision at all. This will give you the highest precision offered in your games no matter what.
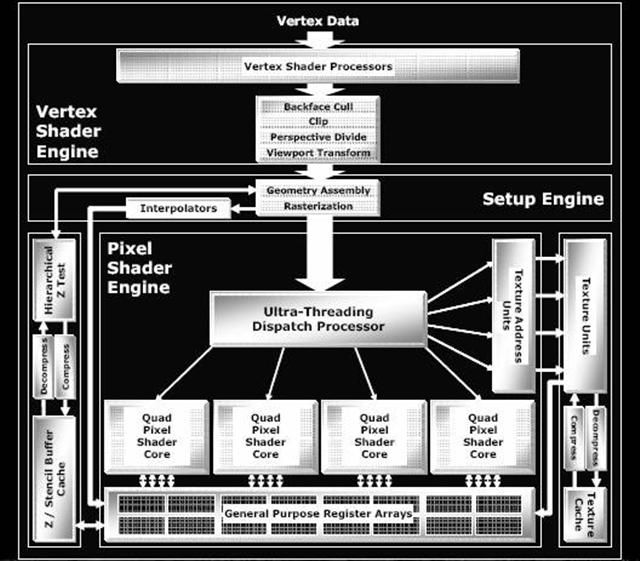
Here is the complete layout of the X1000 series architecture. Looking at this layout, you can see that ATI has restructured their processing units and moved away from the more traditional video card pipeline. There is still the ?Vertex Pipeline,? ?Pixel Pipeline,? and what they call ?Render Back-End Units.” While these are still pipelines, they are more like separate processors. GPU’s are ever increasing in complexity now and are quite flexible in what you can do with the Arithmetic Logic Units (ALUs) within each pixel or vertex pipeline.
This means that you can’t simply look at the raw number of “pipelines” to tell you how an architecture will perform. Judgments should be based on real world gameplay testing.
Vertex Processing Units

The Radeon X1800 series contains 8 vertex shader processors. Each one is capable of Vertex Shader 3.0 and Dynamic Flow Control. Each vertex processor can process one 128-bit vector instruction plus one 32-bit scalar instruction per clock cycle. When combined, the 8 vertex processors can transform up to 2 vertices every clock cycle. This means that the X1800 has the ability to process 10 billion vertex shader instructions per second.
Pixel Processing Units
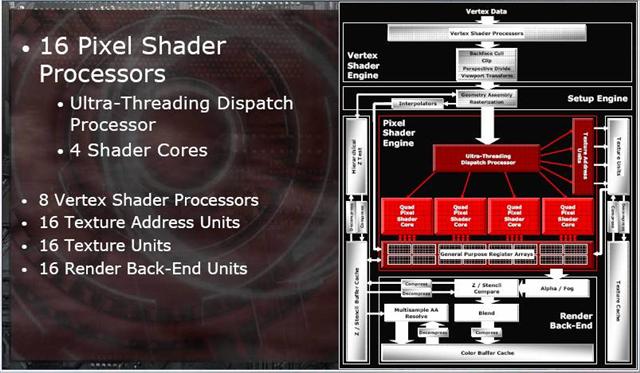
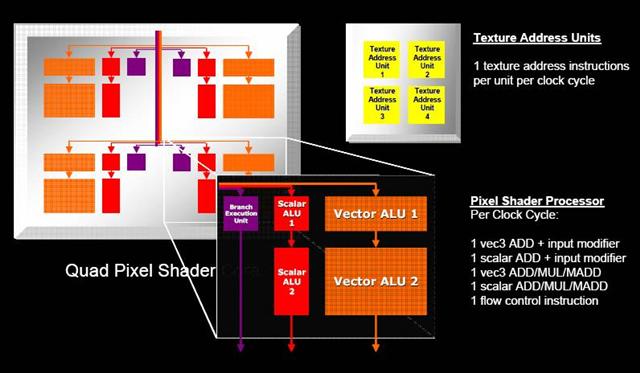
ATI now also has full support for Pixel Shader 3.0 and is employing a new Ultra-Threaded design for the pixel-pipeline of the architecture. A Dispatch Processor sends threads where they need to go in the pipeline. This should improve dynamic branching and flow control performance. In the Radeon X1800 XL and XT, there are four groups of Quad Pixel Shader cores (Quads) to make what would normally be 16 pipelines. Each pixel shader processor is capable of performing up to two vector operations and two scalar operations per each clock cycle. Each pixel shader engine includes a set of 16 texture address ALUs which can be used to perform texture operations without tying up the pixel shader cores. The dispatch processor itself has sequencing logic that can arrange shader code to maximize the utilization of each ALU. Each core has its own dedicated branch execution unit that can execute one flow control operation per clock cycle in parallel with the others. The X1800 models have the ability to execute up to 6 pixel shader instructions per clock cycle on 16 pixels simultaneously. Each shader processor can perform 2 scalar instructions, 2 3-component vector instructions, and a flow control instruction simultaneously.
Flexible Architecture
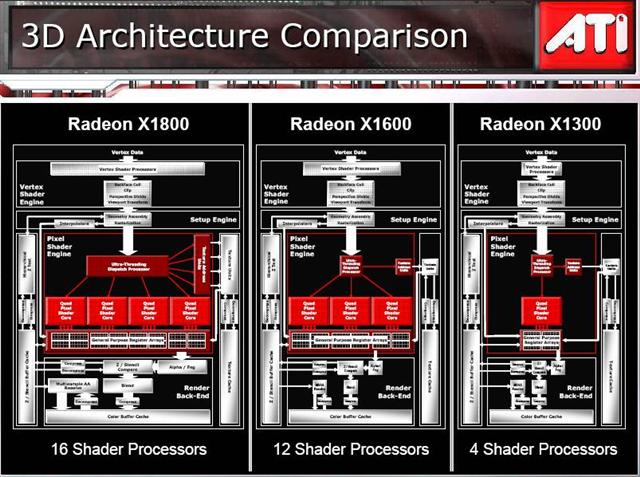
Since the architecture is comprised of Quad Pixel Shader processors with a core in each one, you can drop a quad to make fewer cores. By doing this, ATI is able to reduce die sizes, which means more dies per wafer, in order to meet lower price points. The Radeon X1800 series has 16 pixel shader processors, 8 vertex processors and can do 512 threads per cycle, the X1600 series has 12 pixel shader processors, 5 vertex processors and can do 128 threads per cycle. The X1300 has 4 pixel shader processors, 2 vertex shader processors, and can do 128 threads per clock cycle.
So as you can see, the architecture is very flexible, yet has the exact same feature set across the board and as you’ll see, provides solid performance.
Comments are closed.